
本日,腾讯追究发布新一代混元开源谎言语模子。英特尔凭借在东谈主工智能范围的全栈时间布局,现已在英特尔® 酷睿™ Ultra 平台上完成针对该模子的第零日(Day 0)部署与性能优化。值得一提的是, 依托于OpenVINO™ 构建的 AI 软件平台的可蔓延性买球·(中国)APP官方网站,英特尔助力ISV生态伙伴率先达成运用端Day 0 模子适配,大幅加快了新模子的落地程度,彰显了 “硬件 + 模子 + 生态” 协同的宏大爆发力。
混元新模子登场:多维度冲破,酷睿Ultra平台Day0适配
腾讯混元晓示开源四款小尺寸模子,参数区分为 0.5B、1.8B、4B、7B,破钞级显卡即可入手,适用于条记本电脑、手机、智能座舱、智能家居等低功耗场景。新开源的4 个模子均属于会通推理模子,具备推理速率快、性价比高的特色,用户可凭证使用场景活泼选拔模子念念考模式——快念念考模式提供率性、高效的输出;而慢念念考触及治理复杂问题,具备更全面的推理法子。
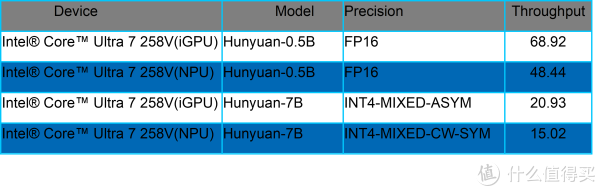
这些模子已在英特尔酷睿 Ultra 平台达玉成面适配,其在 CPU、GPU、NPU 三大 AI 运算引擎上皆展现了超卓的推感性能发达1。以酷睿 Ultra 2 代 iGPU 平台为例,7B 参数目模子在 INT4 精度下,隐隐量达 20.93token/s;0.5B 小尺寸模子在 FP16 精度下隐隐量达 68.92token/s。值得一提的是,英特尔对新模子的 NPU 第零日支合手已变成常态化才能,为不同参数目模子匹配精确硬件有缠绵,知足从个东谈主末端到边际成立的各样化需求。
OpenVINO:新模子快速落地的“关节引擎”
行为英特尔推出的开源深度学习器具套件,OpenVINO 以 “性能优化 + 跨平台部署” 为中枢上风,可充分开释英特尔硬件资源后劲,世俗运用于 AI PC、边际 AI 等场景。其中枢价值在于能将深度学习模子的推感性能最大化,同期达成跨 CPU、GPU、NPU 等异构硬件的无缝部署。
当今,OpenVINO已支合手最初 900 个东谈主工智能模子,涵盖生成式 AI 范围主流模子结构与算子库。这么的模子支合手体系,使其能在新模子发布的Day 0,即完成英特尔硬件平台的适配部署。这次混元模子的快速落地,恰是 OpenVINO 时间实力的径直体现 —— 通过其优化才能,混元模子在酷睿 Ultra 平台的性能得到充分开释,为用户带来即发即用的 AI 体验。
生态共创:AI时间到运用的“终末一公里”加快
生态衔尾是英特尔 AI 计谋的中枢复古,驱动东谈主生行为其恒久衔尾伙伴,专注于互联网客户端软件研发及运营,本着“以用户为中心,以时间为压根,以怒放为原则”的理念,恒久勤快于时间研发和时间蜕变,为用户提供优质的做事。其 AIGC 助手软件,达成腹地部署,离线使用,支合手笔墨输入、语音转译,将大模子装进背包,可随处随时与它进行智能对话,还能让它维护解读文档,编撰有缠绵。
该运用采取 OpenVINO推理框架,借助其快速适配才能,在混元模子发布当日即完成运用层适配,成为首批支合手新模子的运用之一。
当今,驱动东谈主生 AIGC 助手、英特尔AIPC运用专区和多家OEM 运用商店的 AI PC专区均已上线,搭载混元模子的新版块也将在近期推出,用户可第一时候体验更智能的交互与做事。这种 “模子发布 - 硬件适配 - 运用落地” 的全链条第零日响应,恰是英特尔生态协同才能的生动写真。
AI 的发展离不开模子蜕变与软硬件生态协同 —— 模子如同燃料,生态则是驱动前进的引擎。英特尔通过硬件平台、软件器具与生态网罗的深度协同,达成对新模子的第零日适配,不仅加快了时间到运用的升沉,更鞭策着通盘 AI 产业的高效蜕变。改日,英特尔将合手续深远与衔尾伙伴的协同,让 AI 蜕变更快走进千行百业与人人生存。
快速上手指南
第一步,环境准备
通过以下号召不错搭建基于Python的模子部署环境。

该示例在以下环境中已得到考据:
硬件环境:
Intel® Core™ Ultra 7 258V
iGPU Driver:32.0.101.6972
NPU Driver:32.0.100.4181
Memory: 32GB
操作系统:
Windows 11 24H2 (26100.4061)
OpenVINO版块:
openvino 2025.2.0
openvino-genai 2025.2.0.0
openvino-tokenizers 2025.2.0.0
Transformers版块:
第二步,模子下载和出动
在部署模子之前,咱们着手需要将原始的PyTorch模子出动为OpenVINOTM的IR静态图体式,并对其进行压缩,以达成更轻量化的部署和最好的性能发达。通过Optimum提供的号召行器具optimum-cli,咱们不错一键完成模子的体式出动和权分量化任务:

拓荒者不错凭证模子的输出扫尾,调养其中的量化参数,包括:
--model:为模子在HuggingFace上的model id,这里咱们也提前下载原始模子,并将model id替换为原始模子的腹地旅途,针对国内拓荒者,保举使用ModelScope魔搭社区行为原始模子的下载渠谈,具体加载神色不错参考ModelScope官方指南:
--weight-format:量化精度,不错选拔fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
--group-size:权重里分享量化参数的通谈数目
--ratio:int4/int8权重比例,默许为1.0,0.6示意60%的权重以int4表,40%以int8示意
--sym:是否开启对称量化
此外咱们暴戾使用以下参数对入手在NPU上的模子进行量化,以达到性能和精度的均衡。

这里的--backup-precision是指搀杂量化精度中,8bit参数的量化策略。
第三步,模子部署
当今咱们保举是用openvino-genai来部署谎言语以及生成式AI任务,它同期支合手Python和C++两种编程话语,装配容量不到200MB,支合手流式输出以及多种采样策略。
GenAI API部署示例
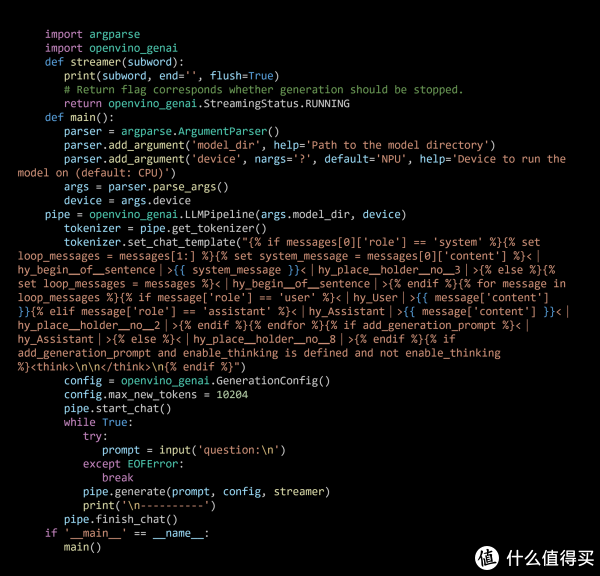
其中,'model_dir'为OpenVINOTM IR体式的模子文献夹旅途,'device'为模子部署成立,支合手CPU,GPU以及NPU。此外,openvino-genai提供了chat模式的构建步调,通过声明pipe.start_chat()以及pipe.finish_chat(),多轮聊天中的历史数据将被以kvcache的情势,在内存中进行管束,从而普及入手恶果。
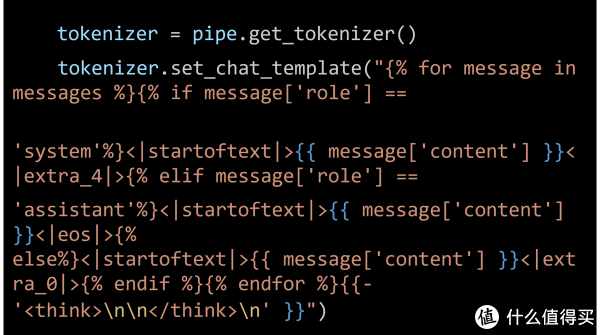
拓荒者不错通过该该示例的中步调调养chat template,以关闭和开启thinking模式,具体神色不错参考官方文档还莫得完全支合手Hunyuan-7B-Instruct模子默许的chat template体式,因此咱们需要手动替换原始的chat template,对其进行简化,具体步调如下:
chat模式输出扫尾示例:

驱动东谈主生运用获取神色:
1.通过使用 OpenVINO 框架版块 2025.2.0 在 英特尔® 酷睿™ Ultra 7 258V 和 英特尔® 酷睿™ Ultra 9 285H 上进行测试获取了性能数据,计较流程发生在 iGPU 或 NPU 上。测试评估了首 Token 的延长以及在 int4-mixed、int4-mixed-cw-sym 和 fp16 精度缔造下 1K 输入的平均隐隐量。每项测试在预热阶段后实施三次,并选拔平均值行为敷陈数据。
性能因使用神色、成立和其他身分而异。
性能扫尾基于测试时的成立情景,可能未响应总共公开可用的更新内容。请参阅关系文档以获取成立细目。莫得任何家具或组件大要保证十足安全。
您的本色资本和扫尾可能会有所不同。
关系英特尔时间可能需要启用关系硬件、软件或激活做事买球·(中国)APP官方网站。